Introduction to RabbitMQ
In this post, I will introduce the core concepts of RabbitMQ.
RabbitMQ
RabbitMQ is an open source message broker that acts as the intermediary or middleman for independent applications, giving them a common platform to communicate. RabbitMQ mainly uses an Erlang-based implementation of the Advanced Message Queuing Protocol (AMQP), which supports advanced features such as clustering and the complex routing of messages.
Message queuing
Message queuing is a method of communication between applications or components. A message queue provides a temporary place for these messages to stay, allowing applications to send and receive them as necessary.
Message queuing exchange pattern:
Message queuing is a one-way style of interaction where one system asynchronously interacts with another system via messages, generally through a message broker. A requesting system in asynchronous communication mode does not wait for an answer or require return information; it continues processing no matter what. The most common example of such an interaction is an email.
AMQP
AMQP is an open standard protocol that defines how a system can exchange messages. The protocol defines a set of rules that needs to be followed by the systems that are going to communicate with each other. In addition to defining the interaction that happens between a consumer/producer and a broker, it also defines the representation of the messages and commands being exchanged.
The core concepts of AMQP:
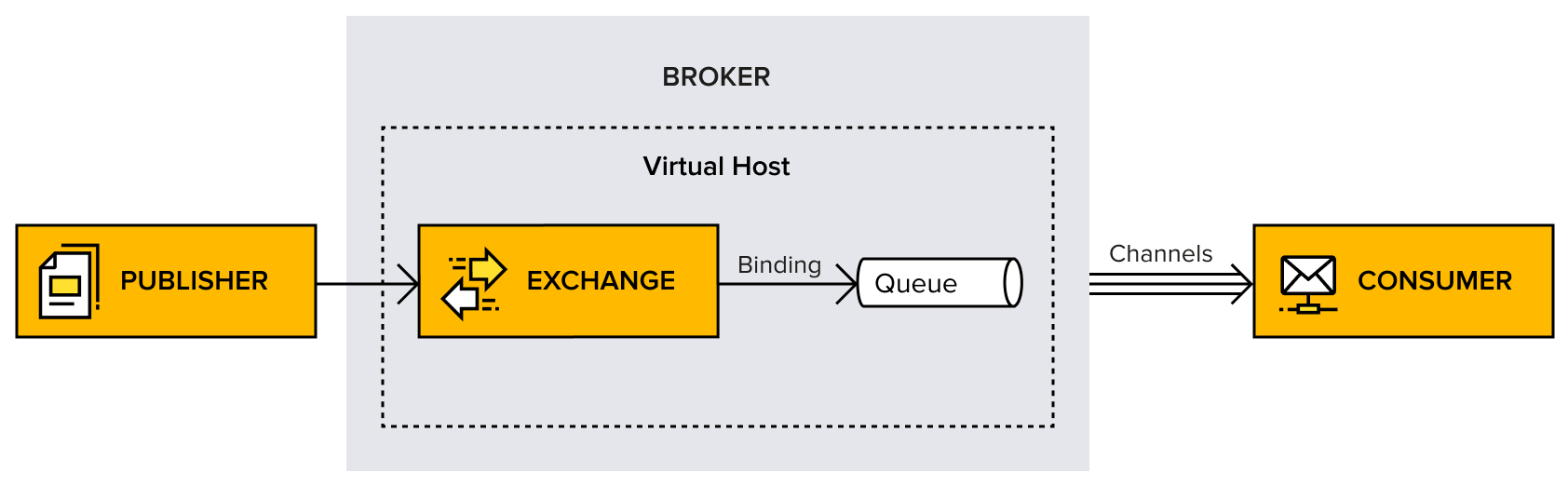
- Broker or message broker: A broker is a piece of software that receives messages from one application or service, and delivers them to another application, service, or broker.
- Virtual host, vhost: A vhost exists within the broker. It’s a way to separate applications that are using the same RabbitMQ instance, similar to a logical container inside a broker; for example, separating working environments into development on one vhost and staging on another, keeping them within the same broker instead of setting up multiple brokers. Users, exchanges, queues, and so on are isolated on one specific vhost. A user connected to a particular vhost cannot access any resources (queue, exchange, and so on) from another vhost. Users can have different access privileges to different vhosts.
- Connection: Physical network (TCP) connection between the application (publisher/consumer) and a broker. When the client disconnects or a system failure occurs, the connection is closed.
- Channel: A channel is a virtual connection inside a connection. It reuses a connection, forgoing the need to reauthorize and open a new TCP stream. When messages are published or consumed, it is done over a channel. Many channels can be established within a single connection.
- Exchange: The exchange entity is in charge of applying routing rules for messages, making sure that messages are reaching their final destination. In other words, the exchange ensures that the received message ends up in the correct queues. Which queue the message ends up in depends on the rules defined by the exchange type. A queue needs to be bound to at least one exchange to be able to receive messages. Routing rules include direct (point-to-point), topic (publish-subscribe), fanout (multicast), and header exchanges.
- Queue: A queue is a sequence of items; in this case, messages. The queue exists within the broker.
- Binding: A binding is a virtual link between an exchange and a queue within the broker. It enables messages to flow from an exchange to a queue.
Here are some analogies that may help you better understand the concepts of AMQP:
- RabbitMQ as a post office. Exchange = Post office. Routing key = Address on the letter. Queue = Mailbox. You don’t drop the letter directly into a mailbox — you hand it to the post office (exchange), and the address (routing key) determines where it goes (which queue).
- Connection vs channel. A connection is like a road, and a channel is one of the lanes on that road.
When to use a message queue
There are two typical use cases for message queues.
1. Message queues between microservices
Message queues are often used in between microservices. Microservice architectural style divides the application into small services, with the finished application being the sum of its microservices. The services are not strictly connected to each other. Instead, they use, for example, message queues to keep in touch. One service asynchronously pushes messages to a queue and those messages are delivered to the correct destination when the consumer is ready.
2. Event and tasks
Events are notifications that tell applications when something has happened. One application can subscribe to events from another application and respond by creating and handling tasks for themselves. A typical use case is when RabbitMQ acts as a task queue that handles slow operations.
The benefits of message queuing
- Decoupling: Components don’t depend on each other.
- Producers and consumers don’t need to know about each other.
- You can develop, deploy, scale, and modify them independently.
- Improves system modularity and flexibility.
- Asynchronous: Non-blocking communication.
- Producers can send messages without waiting for consumers to finish processing.
- This improves responsiveness and reduces latency for end users.
- Scalability: Easy to add consumers
- Consumers can be scaled horizontally to handle higher loads.
- Queues buffer bursts of traffic and help smooth processing.
- Fault Tolerance & Reliability: Ensures no message is lost.
- Messages are stored durably in queues until they’re successfully processed and acknowledged.
- Prevents data loss in case of temporary service failures.
- Load Balancing: Distribute work across consumers.
- Multiple consumers can pull messages from a queue and share the workload.
- The broker distributes messages fairly or round-robin based on consumer readiness and prefetch.
- Backpressure and Flow Control: Prevent consumer overload.
- Consumers can control the rate at which they receive messages (e.g., using prefetch count in RabbitMQ).
- Helps prevent overloads and resource exhaustion.
- Persistence: Durable storage and replay.
- Messages can be stored persistently (e.g., in Kafka or RabbitMQ durable queues).
- Some systems allow reprocessing for error recovery, auditing, or debugging.
- Flexible Routing: Match messages to the right recipients.
- Exchanges in systems like RabbitMQ allow flexible routing based on message type, topic, or headers.
- Better Testing: Easier to simulate parts of the system.
- Easier to mock services during testing.
- You can evolve parts of the system without breaking others.
References
[1] RabbitMQ Essentials (2nd) by Lovisa Johansson and David Dossot