MySQL优化(三):Optimizing Query
This post is talking about MySQL query optimization, if you are familiar with this topic, you can go to the conclusion part that’s a good summary of the query optimization in MySQL that may give you some enlightenment.
Schema optimization and indexing, which are necessary for high performance. But they are not enough, you also need to design your queries well. If your queries are bad, even the best-designed schema and indexes will not perform well.
We need to understand deeply how MySQL really executes queries, so you can reason about what is efficient or inefficient, exploit MySQL’s strengths, and avoid its weakness.
Why Are Queries Slow
Before trying to write fast queries, you need to know the good or bad queries are determined by response time. Queries are tasks, but they are composed of subtasks, and those subtasks consume time. To optimize a query, you must optimize its subtasks by eliminating them, make them happen fewer times, or making them happen more quickly.
You can use profiling a query to find out what subtasks performs to execute a query, and which ones are slow. In general, you can think of a query’s lifetime by following the query through its sequence from the client to the server, where it is parsed, planned, and executed, and then back again to the client. Execution is one of the most important stages in a query’s lifetime. It involves lots of calls to the storage engine to retrieve rows, as well as post-retrieval operations such as grouping and sorting.
While accomplishing all these tasks, the query spends time on the network, in the CPU, in operations (such as statistics and planning, locking, and call the storage engine to retrieve rows).
In every case, excessive time may be consumed because the operations are performed needless, performed too many times, or are too slow. The goal of optimization is to avoid that, by eliminating or reducing operations, or making them faster. For do this optimization, we need to understanding a query’s lifecycle and thinking in terms of where the time is consumed.
Slow Query Basic: Optimize Data Access
The most basic reason a query doesn’t perform well is because it’s working with too much data. We can use the following methods to find out whether your query is access to more data than it needs.
- Find out whether your application is retrieving more data than you need. That means it’s accessing too many rows, or accessing too many columns.
- Find out whether the MySQL server is analyzing more rows than it needs.
Are You Asking the Database for Data You Don’t Need
Some query ask for more data than they need and then throw some of it away. This demands extra work of the MySQL server, adds network overhead, and consumes memory and CPU resources on the application server.
The common mistakes of fetching more data
- Fetching more rows than needed.
- Fetching all columns from a multi-table join.
- Fetching all columns.
- Fetching the same data repeatedly. You don’t need to fetch multiple times for the same data. You could cache it the first time you fetch it, and reuse it thereafter.
Is MySQL Examining Too Much Data
Once you are sure your queries retrieve only the data you need, you can look for queries that examine too much data while generating results. In MySQL, the simplest query cost metrics are:
- Response time.
- Number of rows examined
- Number of rows returned
None of these metrics is a perfect way to measure query cost, but they reflect roughly how much data access to execute a query and translate approximately into how fast the query runs. All three metrics are logged in the query log, so looking at the query log is one of the best ways to find queries that examine too much data.
Response time
Response time is the sum of two things: service time and queue time. Service time is how long it takes the server to actually process the query. Queue time is the portion of response time during which the server isn’t really executing the query–it’s waiting for something, such as I/O, row lock and so forth. As a result, response time is not consistent under varying load conditions. When you look at a query’s response time, you should ask yourself whether the response time is reasonable for the query.
Rows examined and rows return
It’s useful to think about the number of rows examined when analyzing queries, because you can see how efficiently the queries are finding data you need.
However, not all row accesses are equal. Shorter rows are faster to access, and fetching rows form memory is much faster than reading them from disk.
Ideally, the number of rows examined would be the same as the number returned, but in practice this rarely possible. For example, when constructing rows with joins.
Rows examined and access types
MySQL can use several access methods to find and return a row. Some require examining many rows, but others might be without examining any.
The access methods appear in the type column in EXPLAIN’s output. The access types range from a full table scan to index scans, range scans, unique index lookups, and constants. Each of these is faster than the one before it, because it requires reading less data.
If you aren’t getting a good access type, the best way to solve the problem is usually by adding an appropriate index.
In general, MySQL can apply a WHERE clause in three ways, from best to worst:
- Apply the conditions to the index lookup operation to eliminate nonmatching rows. This happen at the storage engine layer.
- Use a covering index (“Using index” in the Extra column of EXPLAIN) to avoid row accesses and filter out nonmatching rows after retrieving each result from the index.
- Retrieve rows from the table, then filter nonmatching rows (“Using where” in the Extra column of EXPLAIN). This happens at the server layer.
Good indexes help your queries get a good access type and examine only the rows they need. However, adding an index doesn’t always mean that MySQL will access fewer rows, or access and return the same number of rows. For example, a query that uses the COUNT() aggregate function.
If you find that a huge number of rows were examined to produce relatively few rows in the result, you can try some more sophisticated fixes:
- Use covering indexes.
- Change the schema.
- Rewrite a complicated query.
Ways to Restructure Queries
As you optimize problematic queries, your goal should be to find alternative ways to get the result you want. You can sometimes transform queries into equivalent forms that return the same results, and get better performance.
Complex Queries Versus Many Queries
It’s a good idea to use as few queries as possible, but sometimes you can make a query more efficient by decomposing it and executing a few simple queries instead of one complex one.
Chopping Up a Query
Another way to slice up a query is to divide and conquer, keeping it essentially the same but running it in smaller “chunks” that affect fewer rows each time.
Purging old data is a great example. For example:
DELETE FROM messages WHERE created < DATE_SUB(NOW(), INTERVAL 3 MONTH); |
It might also be a good idea to add some sleep time between the DELETE statements to spread the load over time and reduce the amount of time locks are held.
Join Decomposition
Many high-performance applications use join decomposition. You can decompose a join by running multiple single-table queries instead of a multitable join. For example:
SELECT * FROM tag |
replace to
SELECT * FROM tag WHERE tag='mysql'; |
Advantages of multiple single-table queries
- Caching can be more efficient.
- Executing the queries individually can sometimes reduce lock contention.
- The queries themselves can be more efficient.
- You can reduce redundant row accesses.
Query Execution Basics
If you need to get high performance from your MySQL server, one of the best ways to learning how MySQL optimizes and executes queries.
The process MySQL to execute queries:
- The client sends the SQL statement to the server.
- The server checks the query cache. If there’s a hit, it returns the stored result from the cache, otherwise to next step.
- The server parses, preprocesses, and optimizes the SQL into a query execution plan.
- The query execution engine executes the plan by making calls to the storage engine API.
- The server sends the result to the client.
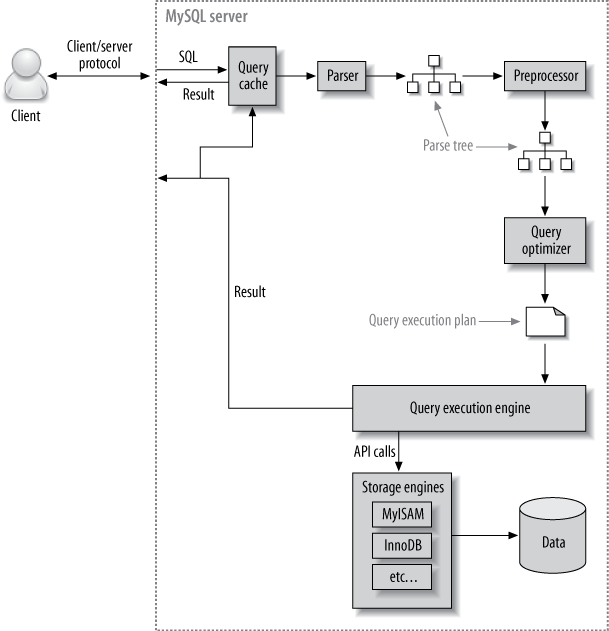
The MySQL Client/Server Protocol
The protocol is half-duplex, which means that at any given time the MySQL server can be either sending or receiving messages, but not both. This protocol makes MySQL communication simple and fast, but it have some limitation. For example, once one side sends a message, the other side must fetch the entire message before responding.
The client sends a query to the server as a single packet of data. So max_allowed_packet configuration variable is important if you have large queries.
In contrast, the response from the server usually consist of many packets of data. When the server responds, the client has to receive the entire result set. Most libraries that connect to MySQL let you either fetch the whole result and buffer it in memory, or fetch each row as you need it.
Query States
Each MySQL connection, or thread, has a state that shows what it is doing at any given time. There are several ways to view these states, but the easiest is to use the SHOW FULL PROCESSLIST command. The basic states in MySQL:
- Sleep
- Query
- Locked
- Analyzing and statistics
- Copying to tmp table [on disk]
- Sorting result
- Sending data
The Query Cache
Before parsing a query, MySQL checks for it in the query cache, if the cache is enabled. This operation is a case-sensitive hash lookup. If the query differs from a similar query in the cache by even a single byte, it won’t match.
If MySQL does find a match in the query cache, it must check privileges before returning the cache query. If the privileges are OK, MySQL retrieves the stored result from the query cache and sends it to the client. The query is never parsed, optimized, or executed.
The Query Optimization Process
After doesn’t find a match in the query cache, the next step in the query lifecycle turns a SQL query into an execution plan for the query execute engine. It has several substeps: parsing, preprocessing, and optimization. Errors (like syntax errors) can be raised at any point in the process.
The parser and the preprocessor
- query parsing: MySQL’s parser breaks the query into tokens and builds a parse tree from them. The parser uses MySQL’s SQL grammar to interpret and validate the query.
- query preprocessing: the preprocessor checks the resulting parse tree for additional semantics. For example, it checks that tables and columns exist, and it resolves names and aliases to ensure that column references aren’t ambiguous. Next, the preprocessor checks privileges.
The query optimizer
After preprocessing the parse tree is now valid and ready for the optimizer to turn it into a query execution plan. A query can often be executed many different ways and produce the same result. The optimizer’s job is to find the best option.
MySQL uses a cost-based optimizer, which means it tries to predict the cost of various execution plans and choose the least expensive. The unit of cost way originally a single random 4KB data page read, but also includes factors such as the estimated cost of executing a WHERE clause comparison. You can see how expensive the optimizer estimated a query to be by running the query, then inspecting the Last_query_cost session variable:
SELECT SQL_NO_CACHE COUNT(*) FROM your_table; |
Result of SHOW STATUS LIKE 'Last_query_cost' means that the optimizer estimated it would need to do about how much random data page reads to execute the query.
The optimizer might not always choose the best plan, for many reasons:
- The statistics could be wrong.
- The cost metric is not exactly equivalent to the true cost of running the query.
- MySQL’s idea of optimal might not match yours. MySQL doesn’t really try to make queries fast; it tries to minimize their.
- MySQL doesn’t consider other queries that are running concurrently.
- MySQL doesn’t always do cost-based optimization.
- The optimizer doesn’t take into account the cost of operations not under its control, such as executing stored functions.
MySQL’s join execution strategy
MySQL consider every query a join–not just every query that matches rows from two tables, but every query. It’s very important to understand how MySQL executes joins.
MySQL’s join execution strategy is simple: it treats every join as a nested-loop join. This means MySQL runs a loop to find a row from a table, then run a nested loop to find a matching row in the next table. It continues until it has found a matching row in each table in the join. For example:
SELECT tab1.col1, tab2.col2 |
following pseudocode shows how MySQL might execute the query:
outer_iter = iterator over tbl1 where col1 IN(5,6) |
First Finding table iterator that fulfills the WHERE condition, then finding equal values on join columns.
The execution plan
MySQL doesn’t generate byte-code to execute a query, instead, the query execution plan is actually a tree of instructions that the query execution engine follows to produce the query results.
Any multitable query can conceptually be represent as a tree. MySQL always begins with one table and finds matching rows in the next table. Thus, MySQL’s query execution plans always take the form of left-deep tree. As shown in the figure below.
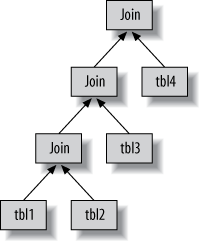
The join optimizer
The most important part of the MySQL query optimizer is the join optimizer, which decides the best order of execution for multitable queries.
MySQL’s join optimizer can reorder queries to make them less expensive to execute. You can use STRAIGHT_JOIN and write queries in the order you think is best, but such times are rare. In most cases, the join optimizer will outperform a human.
Sort optimizations
Sorting results can be a costly operation, so you can often improve performance by avoiding sorts or by performing them on fewer rows.
When MySQL can’t use an index to produce a sorted result, it must sort the rows itself. It can do this in memory or on disk, but it always calls this process a filesort, even if it doesn’t actually use a file.
If the values to be sorted will fit into the sort buffer, MySQL can perform the sort entirely in memory with a quiksort. If MySQL can’t do the sort in memory, it performs it on disk by sorting the values in chunks with quicksort, and then merges the sorted chunks into results.
When sorting a join, if the ORDER BY clause refers only to columns from the first table in the join order, MySQL can filesort this table and then proceed with the join. This case will show “Using filesort” in the Extra column of EXPLAIN. If ORDER BY clause contains columns from more than one table, MySQL must store the query’s results into a temporary table and then filesort then temporary table after the join finishes. This case will show “Using temporary; Using filesort” in the Extra column of EXPLAIN.
The Query Execution Engine
The parsing and optimizing stage outputs a query execution plan, which MySQL’s query execution engine uses to process the query. The plan is a data structure; it is not executable byte-code, which is how many other database execute queries.
In contrast to the optimization stage, the execution stage is usually not all that complex: MySQL simply follows the instructions given in the query execution plan. Many of the operations in the plan invoke methods implemented by the storage engine interface, also known as the handler API.
To execute the query, the server just repeats the instructions until there are no more rows to examine.
Returning Results to the Client
The final step in executing a query is to reply to the client. Even queries that don’t return a result set still reply to the client connection with information about the query, such as how many rows it affected.
The server generates and sends results incrementally. As soon as MySQL processes the last table and generates one row successfully, it can and should send that row to the client. This has two benefits: it lets the server avoid holding the row in memory, and it means the client starts getting the results as soon as possible. Each row in the result set is sent in a separate packet in the MySQL client/server protocol, although protocol packets can be buffered and sent together at the TCP protocol layer.
Limitations of the MySQL Query Optimizer
Correlated Subqueries
MySQL sometimes optimizes subqueries very badly. The worst offenders are IN() subqueries in the WHERE clause.
The standard advice for this query is to write it as a LEFT OUTER JOIN instead of using a subquery.
UNION Limitations
You should put condition clauses inside each part of the UNION.
For example, if you UNION together two tables and LIMIT the result to the first 20 rows:
Query 1:
This query will store all rows of tables into a temporary table then fetch first 20 rows form that temporary table.
(SELECT first_name, last_name |
Query 2:
This query will store first 20 rows each table into a temporary table and then fetch first 20 rows from that temporary table.
(SELECT first_name, last_name |
You should use query 2 (contains inside LIMIT) instead of query 1 (only outer LIMIT).
SELECT and UPDATE on the Same Table
MySQL doesn’t let you SELECT from a table while simultaneously running an UPDATE on it. To work around this limitation, you can use a derived table, because MySQL materializes it as a temporary table.
UPDATE tb1 AS outer_tb1 |
To
UPDATE tb1 |
Query Optimizer Hints
MySQL has a few optimizer hints you can use to control the query plan if you are not content with the one MySQL’s optimizer chooses. You place the appropriate hint in the query whose plan you want to modify, and it is effective for only that query. Some of them are version-dependent. You can check the MySQL manual for the exact syntax of each hint.
STRAIGHT_JOIN. Putting this hint in after the SELECT keyword that forces all tables in the query to be joined in the order in which they are listed in the statement. Putting in between two joined tables that force a join order on the two tables between which the hint appears. It is useful when MySQL doesn’t choose a good join order, or when the optimizer takes a long time to decide on a join order.
select a.id, c.id |
or
select straight_join a.id, c.id |
USE INDEX, IGNORE INDEX, and FORCE INDEX. These hints tell the optimizer which indexes to use or ignore for finding rows in a table.
Optimizing Specific Types of Queries
There are some advice on how to optimize certain kinds of queries. Most of the advice is version-dependent, and it might not hold for future versions of MySQL.
Optimizing COUNT() Queries
Before optimization, it’s important that you understand what COUNT() really does.
The COUNT() counts how many times that expression has a value. When you want to know the number of rows in the result, you should always use COUNT(*).
Simple Optimizations
Example 1:
SELECT COUNT(*) FROM world.City WHERE ID > 5; |
replace to
SELECT (SELECT COUNT(*) FROM world.City) - COUNT(*) |
Example 2:
SELECT SUM(IF(color = 'blue', 1, 0)) AS blue,SUM(IF(color = 'red', 1, 0)) AS red FROM items; |
replace to
SELECT COUNT(color = 'blue' OR NULL) AS blue, COUNT(color = 'red' OR NULL) AS red FROM items; |
Using an approximation
Sometimes you don’t need an accurate count, so you can just use an approximation. The optimizer’s estimated rows in EXPLAIN often serves well for this. Just execute an EXPLAIN query instead of the real query.
EXPLAIN select COUNT(*) from your_table; |
Fast, accurate, and simple: pick any two.
Optimizing JOIN Queries
There are some principles for optimizing JOIN queries:
- Make sure there are indexes on the columns in the ON or USING clauses. Consider the join order when adding indexes. In general, you need to add indexes only on the second table in the join order (for example, table A join B, you need add index on B rather than A), unless they’re needed for some other reason.
- Try to ensure that any GROUP BY or ORDER BY expression refers only to columns from a single table, so MySQL can try to use an index for that operation.
- Be careful when upgrading MySQL, because the join syntax, operator precedence, and other behaviors have changed at various time.
Optimizing Subqueries
The core of the post is focused on MySQL 5.1 and MySQL 5.5. In these versions of MySQL, and in most situations, you should usually prefer a join where possible, rather than subqueries. However, prefer a join is not future-proof advice, so you need be cautious with it.
Optimizing GROUP BY and DISTINCT
MySQL optimizing these two kinds of queries similarly in many cases, and in fact converts between them as needed internally during then optimization process.
MySQL has two kinds of GROUP BY strategies when it can’t use an index: it can use a temporary table or file sort to perform the grouping. Either one can be more efficient for any given query. You can force the optimizer to choose one method or the other with the SQL_BIG_RESULT and SQL_SMALL_RESULT optimizer hints.
If you need to group a join by a value that comes from a lookup table, it is usually more efficient to group by the lookup table’s identifier than by value.
SELECT actor.first_name, actor.last_name, COUNT(*) |
Replace to
SELECT actor.first_name, actor.last_name, COUNT(*) |
It’s generally a bad idea to select nongrouped columns in a grouped query, because the results will be nondeterministic and could easily change if you change an index or the optimizer decides to use a different strategy. It’s better to be explicit. We suggest you set the server’s SQL_MODE configuration variable to include ONLY_FULL_GROUP_BY so it produces an error instead of letting you write a bad query. Query select values only are grouped columns or aggregate function on grouped columns. For example:
SELECT name, COUNT(*) FROM your_table GROUP BY name; |
MySQL automatically orders grouped queries by the columns in the GROUP BY clause, unless you specify an ORDER BY clause explicitly. If you don’t care about the order and you see this causing a filesort, you can use ORDER BY NULL to skip the automatic sort.
Optimizing GROUP BY WITH ROLLUP
A variation on grouped queries is to ask MySQL to do superaggregation within the results. You can do this with a WITH ROLLUP clause, but it might not be as well optimized as you need. Check the execution method with EXPLAIN , paying attention to whether the grouping is done via filesort or temporary table; try removing the WITH ROLLUP and seeing if you get the same group method.
Sometimes it’s more efficient to do superaggregation in your application, even if it means fetching many more rows from the server.
Optimizing LIMIT and OFFSET
Queries with LIMITs and OFFSETs are common in systems that do pagination, nearly always in conjunction with an ORDER BY clause. It’s helpful to have an index that supports the ordering; otherwise, the server has to do a lot of filesorts.
A frequent problem is having high value for offset. For example, if you query looks like LIMIT 10000, 20, it is generating 10020 rows and throwing away the first 10000 of them, which is very expensive. To optimize them, you can either limit how many pages are permitted in a pagination view, or try to make the high offsets more efficient.
The key of optimizing do pagination is using an index to sort rather than using a filesort. You can use join or using some methods to replace the OFFSET.
- using index for sort
- Using join.
SELECT * FROM ... JOIN (SELECT id ... ORDER BY .. LIMIT off, count) - Remove offset.
SELECT * ... ORDER BY ... LIMIT count - Remove offset and limit.
SELECT * ... WHERE <column> BETWEEN <start> AND <end> ORDER BY ...
- Using join.
- Using filesort
SELECT * ... ORDER BY ... LIMIT offset, row_count
- Optimizing sort by using joins
One ways to optimizing the high value offset is offset on a covering index, rather than the full rows. You can then join the result to the full row and retrieve the additional columns you need. For example:
SELECT film_id, description FROM sakila.film ORDER BY title LIMIT 50, 5; |
replace to
SELECT film.film_id, film.description |
SELECT id FROM your_table ORDER BT title can use the covering index(title, id). However, SELECT * ... ORDER BY title have no index to use because in general there is no covering all column index in a table, and it has to using filesort.
- Optimizing offset by using positional range queries
Limit to a positional query, which the server can executes as an index range scan. For example:
SELECT film_id, description FROM sakila.film |
- Using a start position instead of an OFFSET
If you use a sort of bookmark to remember the position of the last row you fetch, you can generate the next set of rows by starting from that position instead of using an OFFSET.
first page query
SELECT * FROM sakila.rental |
next page query
SELECT * FROM sakila.rental |
Optimizing UNION
MySQL always executes UNION queries by creating a temporary table and filling it with the UNION results. MySQL can’t apply as many optimizations to UNION queries as you might be used to. You might have to help the optimizer by manually pushing down WHERE, LIMIT, ORDER BY, and other conditions because you can’t use index in temporary tables. For example, copying them, as appropriate, from the outer query into each SELECT in the UNION.
It’s important to always use UNION ALL, unless you need the server to eliminate duplicate rows. If you omit the ALL keyword, MySQL adds the distinct option to the temporary table, which uses the full row to determine uniqueness. This is quite expensive.
Static Query Analysis
Percona Toolkit contains pt-query-advisor, a tool that parses a log of queries, analyzes the query patterns, and gives annoyingly detailed advice about potentially bad practices in them. It will catch many common problems such as those we’ve mentioned in the previous sections of this post.
Conclusion
For query optimization, we should understanding query execution basic such as what is a general query execution process in MySQL.
Before we to optimize a query, we must find the reason of slow to a query. We can use EXPLAIN to see how the query to execute. However a slow query may cause by many reasons which are schema of table, indexes of table, and the query statement. We need to combine these aspects to optimize.
We know query optimization that is part of optimization. In theory, MySQL will execute some queries almost identically. In reality, measuring is the only way to tell which approach is really faster. For query optimization, There are some advice on how to optimize certain kinds of queries. Most of the advice is version-dependent, and it might not hold for future versions of MySQL.
Appendixes
Common Types of Query
- Single Table Query
- JOIN
- UNION, UNION ALL
- Subquery
Efficiency of Queries
Efficiency of kinds of single table query from high to low:
- Extra: Using index. Using covering index. (lookup in an index, fetch data from an index file).
- Extra: (isn’t Using index). That means don’t fetch data from index file.
- type: ref (or type: range, Extra: Using index condition). Using index to find all columns of rows (lookup in an index, fetch data from a table file).
- type: index_merge. Using multiple index to find all columns of rows (lookup in multiple indexes, fetch data from a table file). For example,
select * from <table_name> where <column in index1> = <value1> or <column in index2> = <value2>. - type: index. To scan an index (Scan an index, fetch data from a table file).
- type: range, Extra: Using where. Using index find all columns of rows, and the MySQL server is applying a WHERE filter after the storage engine returns the rows. (lookup in an index, fetch data from a table file, and filter data by MySQL server). For example,
SELECT * FROM <table> WHERE id > 5 AND id <> 1. - type: ALL. To scan an table file.
- type: ALL, Extra: Using where. To scan an table. For example,
SELECT * FROM <table> WHERE <column not in index> > "". - type: ALL, Extra: Using where, Using filesort. To scan an table, and do a filesort. For example,
SELECT * FROM <table> WHERE <column not in index> > "" order by <column not in index>.
- type: ALL, Extra: Using where. To scan an table. For example,
Internal Temporary Table
In some cases, the server creates internal temporary tables while processing statement. To determine whether a statement requires a temporary table, use EXPLAIN and check the Extra column to see whether it says Using temporary
- Evaluation of UNION statements, when UNION DISTINCT, or have a global ORDER BY clause.
- Evaluation of derived tables.
- Evaluation of common table expressions (WITH)
- Evaluation of statements that contain an ORDER BY clause and a different GROUP BY clause, or for which the ORDER BY or GROUP BY contains columns from tables other than the first table in the join queue.
- Evaluation of subquery has no indexes.
- Evaluation of DISTINCT combined with ORDER BY may require a temporary table.
- For queries that use the SQL_SMALL_RESULT modifier, MySQL uses an in-memory temporary table, unless the query also contains elements that require on-disk storage.
- To evaluate INSERT … SELECT statements that select from and insert into the same table.
- Evaluation of multiple-table UPDATE statements.
- Evaluation of window functions uses temporary tables as necessary.
Some query conditions prevent the use of an in-memory temporary table, in which case the server uses an on-disk table instead:
- Presence of a BLOB or TEXT column in the table.
- Presence of any string column with a maximum length larger than 512 bytes or characters in SELECT.
- The SHOW COLUMNS and DESCRIBE statements use BLOB as the type for some columns.
Format of SELECT Statement
SELECT |
References
[1] High Performance MySQL by Baron Schwartz, Vadim Tkachenko, Peter Zaitsev, Derek J. Balling
[2] MySQL 8.0 Reference Manual