深入理解数据库系统(二):关系型数据库
本篇将介绍关系型数据库,数据库查询语言(SQL 语言)和形式关系查询语言。你将了解关系型数据库的详细内容,SQL 语句的使用,以及形式关系查询语言的用法。
介绍关系型模型
关系型模型是如今商业的数据处理应用程序的主要数据模型。关系型模型因其简单易用的特点被广泛使用。
关系型数据库的结构
关系型数据库是一组表(Table)组成,每一个表分配一个唯一的名称。
关系型模型中,术语关系(Relation)用于参考数据库的表(Table),术语元组(Tuple)用于参考数据库的行(Row),术语属性(Attribute)参考数据库的列(Column)。术语关系实例(Relation Instance)参考数据的实例。一个关系由多个元组构成。一个元组由多个属性值构成。每一个属性的取值范围称为域(Domain)。所有的属性的域是原子的、不可分的。null 值是一个特殊的值,它表示未知或者不存在。
数据库模式
数据库的表现形式可以分为逻辑的和物理的。数据库模式(Database Schema)是数据库的逻辑设计。数据库实例(Database Instance)表示数据库某个时刻的数据的快照。数据库模式由一组属性和对应的域组成。
键
我们必须有一种方法去区分一个关系中的不同的元组。Superkey 是一个或多个属性组合,它可以唯一的标识关系中的一个元组。如,在关系型数据库中我们常用 ID 来标识一个行记录。没有子集 Superkey 的 Superkey ,这种最小的 Superkey 称为 候选键(Candidate Key)。在数据库中我们使用术语主键(Primary Key)来表示数据库设计人员选择的候选键。在一个关系中的任何两个元组不允许出现相同的 key 属性值。
一个关系 r1 的属性是另一个关系 r2 的主键,这个属性称为外键(Foreign Key)。参考完整性约束(Referential Integrity Constraint)表示一个外键属性值出现在参考关系中,它也必须出现在被参考的关系中。
模式图
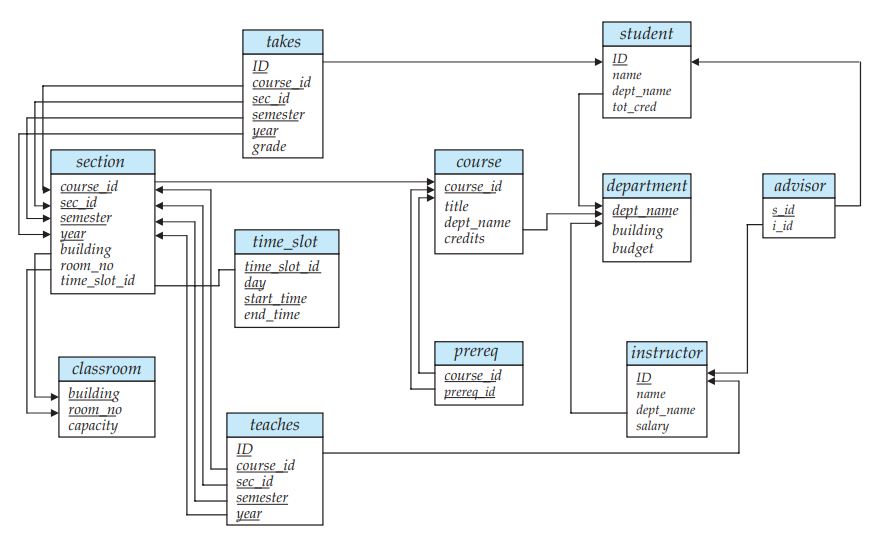
数据库的主键和外键依赖可以通过模式图(Schema Diagram)来表示。每个关系用一个矩形表示,主键属性添加下划线表示,外键依赖表示为从外键属性出发的带箭头的线指向被参考的关系的主键属性。一个数据库模式图的例子,如下图所示。
数据库查询语言
数据库查询语言包括过程和非过程的。
非过程查询语言(Nonprocedural Language)是指用户描述希望得到的信息,但没有给出一个获得信息的具体的过程。常见的非过程查询语言,如 SQL (Structured Query Language),关系演算(relational calculus)。
过程查询语言(Procedural Language)是指用户指定了执行一系列的操作计算得到希望的结果。常见的过程查询语言,如关系代数(relational algebra)。
本篇接下来会详细的介绍以上数据库查询语言的用法。
关系型操作
过程的关系型查询语言提供了一组操作应用在一个关系或者多个关系中。关系查询的结果本身是一个关系,因此关系运算可以应用于查询结果以及给定的一组关系。具体的关系型操作的表达取决于具体的查询语言。
常见的操作有,选择(select),投影(project),连接(join),笛卡尔积(Cartesian Product),组合(Union),相交(Intersect)等等。这些操作会在下面的关系代数查询语言中详细介绍。
介绍 SQL
有大量的数据库查询语言可以使用。SQL 是目前最广泛使用的一种查询语言。SQL 不仅能查询数据库,它也可以定义和修改数据库。
SQL 语言概述
IBM 开发了初始版本的 SQL,原名为 Sequel。Sequel 语言经过发展,它的名称变成了 SQL (Structured Query Language)。1986年 国际标准组织(ISO)发布了一个 SQL 标准,称为 SQL-86。后续陆续发布了很多个 SQL 标准版本,最近的一个版本为 SQL:2008。
SQL 语言由多个部分组成:
- 数据定义语言(Data-Definition Language, DDL),它可以定义、删除和修改关系模式(relation schema)。
- 数据操纵语言(Data-Manipulation Language, DML)它可以查询,插入,删除和修改数据库的元组。
- 完整性(Integrity)。DDL 包含语句可以指定数据的完整性约束。
- 视图定义。DDL 包含语句可以定义视图。
- 事务控制。SQL 包含命令可以指定事务的开始和结束。
- 嵌入的 SQL 或动态的 SQL。它可以嵌入在编程语言中如 C, C++, Java 进行操作数据库。
- 授权(Authorization)。DDL 包含语句可以指定关系和视图的访问权限。
每个数据库系统实现的 SQL 与标准的 SQL 有一些小差异,但大部分是标准的,SQL 的功能组成也大致一样。特定的数据库系统中的不标准的 SQL 可以查阅数据库系统的用户手册。
SQL 数据定义
数据库中的一组关系必须通过数据定义语言(DDL)来指定给数据库系统。SQL DDL 可以定义:
- 每个关系的模式(Schema)
- 每个属性的类型。
- 完整性约束。
- 每个关系的一组索引。
- 每个关系的安全和授权信息。
- 每个关系的物理存储结构。
基本类型
SQL 标准支持大量的内置类型,包括:
- char(n):固定长度 n 的字符串。
- varchar(n):可变长度的字符串,最大长度为n。
- int:一个整数。与硬件相关的整数的有限子集。
- smallint:一个小的整数。
- numeric(p, d):指定精度和固定的小数部分的数。该数据有p位数字(加一个符号)组成,p 位数字中的 d 位在小数据的右边。如,numeric(3, 1) 可以表示 44.5,不可以表示 444.5,4.45 等。
- real, double precision:浮点数和双精度浮点数。具体精度与硬件相关。
- float(n):一个浮点数,精度至少为 n 位。
每一种类型可以包含一个特殊的值称为 null。null 表示未知或者不存在。
char 数据类型存储固定长度的字符串,当字符串长度不够时,自动在字符串后面加空格。
char 和 varchar 等类型的字符串之间比较时,先转换为相同的长度,再进行比较。
SQL 也支持 nvarchar 类型,它是字符串类型,它存储的是 Unicode 编码或者多语言数据。而 varchar存储的是 ASCII 数据。nvarchar 一个字符使用 2 个字节,varchar 一个字符使用 1 个字节。然而,很多数据库允许 Unicode (UTF-8)的数据存储在 varchar 类型中。
基本的模式定义
SQL 使用 create table 语句创建一个数据库的关系。如
create table department |
SQL 可以指定完整性约束:
- primary key(Aj1, Aj2…)
- foreign key(Ak1, Ak2…)
- not null
插入元组语句:
insert into instructor |
删除元组语句:
delete from student; |
删除表语句:
drop table r; |
修改表语句。如,添加属性和删除属性。
alter table r add A D; |
基本的 SQL 查询操作
基本的 SQL 查询语句有三个子句(Clause):select,from 和 where。
一个关系中的查询
使用 select from where 三个基本的子句进行单表查询
select name |
使用关键字 distinct 去除重复的记录,关键字 all 允许重复的结果。
select distinct dept_name |
select 子句支持算术表达式
select ID, name, dept_name, salary * 1.1 |
where 子句支持逻辑连词,and, or, not
select name |
多个关系的查询
典型的多个关系的 SQL 查询语句
select A1, A2,..., An |
多个关系的查询使用 from 子句指定查询哪些关系。
from 子句多表查询的过程:
生成一个
from子句中的所有关系的笛卡尔乘积(Cartesian Product)。基于步骤1产生的结果,使用
where子句的断言进行筛选元组。基于步骤2产生的结果,输出
select子句指定的属性。
多个关系的连接查询
natural join:创建一个连接基于两个关系中相同名称的属性具有相同的属性值。连接后的关系中相同的属性只显示一次。natural join 一般默认是 inner join。
join 和 from 多表查询可以得到相同的结果,但 join 写法更简洁。natural join 语句如下
select A1, A2,..., An |
join 的实现是通过将两个关系按特定属性排序后进行连接的,不会生成笛卡尔积,但是需要对关系表进行排序。Cartesian product 一个是空间消耗,join 一个是时间消耗。
其它基本的 SQL 查询操作
重命名
as 关键字可以重命名结果关系中的属性名称,以及重命名 SQL 语句中的关系名称,如 old-name as new-name。新的名称可以称为别名 (alias)。
select T.name as instructor_name, S.course_id |
字符串操作
比较操作:SQL 标准中字符串比较是区分大小写的,但是常见的数据库系统,如 MySQL 和 SQL Server 中不区分大小写。
字符串函数:SQL 支持大量的字符串函数,如:转换大小写 upper(s), lower(s),去除开始和结尾的空格 trim(s)。每个数据库系统中的字符串函数不一样,具体参照特定的数据库系统手册。
模式匹配:可以使用 like 操作符进行字符串的模式匹配。字符串中的 % 匹配一个或多个任意字符,_ 匹配任何一个字符。
select dept_name |
转义符:SQL 使用反斜杠 \ 进行转义字符(Escape Character)。
正则表达式:SQL 标准支持比 like 操作更强大的模式匹配,在 SQL 中可以使用正则表达式。
select 子句中的属性规范
符号 * 再 select 子句中表示一个关系的所有属性。
select instructor.* |
排序
SQL 支持对一个关系中的元组进行排序,使用 order by 子句可以对查询结果的元组进行排序。
select name |
where 子句的断言
SQL 中的 where 子句支持 between 操作符进行比较断言。between 可以代替 算术操作符 >=, <=
select name |
比较运算符可以支持元组,即多个属性按顺序比较。如, (a1, a2) < (b1, b2), (a1, a2) = (b1, b2)
集合操作
常见的集合操作(Set Operations)如:组合 union,相交intersect 和排除 except。集合操作默认会去除重复的记录,添加 all 关键字,可以允许重复的记录。如 union all,intersect all, except all 等。一个集合操作的 SQL 语句例子如下:
(select course_id |
Null 值
Null 值在关系型操作中是一个特殊问题,Null 值表示的是未知或不存在。Null 值在算术操作,比较操作,和逻辑操作视为特殊情况。可以把 Null 值理解为一个未知的值。
算术操作
算术操作中包含 null 的表达式,返回结果为 null。如 null + 5 // result is null. 表示的是: 未知 + 5,结果是未知。
比较操作
比较操作包含 null 时,结果既不是 true 也不是 false,而是未知。返回结果为 null。如 1 < null //result is null。表示的是:1 是否小于未知,结果是未知。
逻辑操作
where 子句中的逻辑连接是出现 null。
- and.
true and null is null,false and null is false,null and null is null - or.
true or null is true,false or null is null,null or null is null - not.
not null is null
可以使用 select 子句去测试结果,如
select true and null; // return null |
测试属性值是否为空
使用 is null 和 is not null 来测试值是否为空。不能用等号来测试属性属性是否为空,因为 null = null // result is null。一个 SQL 例子如下:
select name |
聚合函数
聚合函数(Aggregate Function)是一个函数把一组值作为输入,返回一个值。SQL 提供5个内置聚合函数:
- 平均值:avg
- 最小值:min
- 最大值:max
- 总和:sum
- 数量:count
sum 和 avg 函数的输入必须是数字。其它的函数输入的可以是数字和非数字,如字符串。
基本的聚合
select avg (salary) |
select count (distinct ID) |
count(*) 表示查询一个关系的元组的数量。
select count (*) |
分组聚合
聚合函数不仅可以使用在单个元组集合中,也可以使用在多个元组集合中。SQL 使用 group by 子句进行分组。它根据 group by 子句指定的所有属性的相同属性值进行分组。一个分组聚合的 SQL 例子:
select dept_name, avg (salary) as avg_salary |
注意事项:使用分组查询时,select 子句中出现的属性必须是 group by 中出现的属性。其它属性不能直接出现在 select 子句中,可以出现在聚合函数里。如,上面的 SQL,group by dept_name,所以 select 子句只能出现 dept_name 属性和聚合函数
select dept_name, avg (salary)。原因:对某些属性进行分组,目的只能是计算这些分组的聚合函数结果。在分组查询的结果中,分组的属性和未分组的属性是一对多的关系,无法在一行中表示,所以 select 子句中不允许出现不是 group by 的属性。
Having 子句
having 子句使用聚合函数对分组进行过滤。SQL 语句例子如下:
select dept_name, avg (salary) as avg_salary |
一个分组查询包含 having 子句的查询处理过程:
- 根据 from 子句得到关系的所有元组。
- 如果 where 子句存在,则根据 where 子句的断言,过滤 from 子句中的元组。
- 根据 group by 子句对元组进行分组。
- 根据 having 子句过滤分组。
- 根据 select 子句中的聚合函数,得出每个分组的查询结果。
聚合函数中的 Null 和 Boolean 值
Null 值
除了 count() 函数之外的所有聚合函数,都忽略 null 值的输入。
select sum(salary) |
上面 SQL 语句中的 sum(salary) ,如果分组中某个元组的 salary 属性值为 null,这个元组将被忽略。即 null 值不参与聚合函数的计算。
嵌套子查询
嵌套的子查询可以嵌套在 select 子句,from 子句,where 子句和 having 子句。
集合成员(Set Membership)
in 关键字可以测试一个值是否是一个集合的成员。这个集合是由 select 子句产生的。测试不是一个集合成员使用 not in关键字。
select distinct course_id |
集合对比(Set Comparison)
测试一个值至少大于一个集合中的一个值使用 > some 关键字,测试大于一个集合中的所有值使用 > all 关键字。这个集合同样是 select 子句产生的。
select name |
测试空关系
使用 exists 关键字测试一个子查询的结果是否由存在元组。如果子查询结果为空,则返回 false,不为空则返回 true。
select course_id |
测试是否存在重复元组
使用 unique 关键字可以测试子查询是否存在重复的元组。存在重复返回 true,不存在则返回 false。not unique 测试是否不存在重复。
select T.course_id |
子查询在 from 子句
select dept_name, avg_salary |
with 子句
with 子句可以定义一个临时的关系。
with max_budget (value) as |
标量子查询
SQL 允许子查询嵌入 select 子句中,子查询必须返回一个元组中的一个属性,这个子查询称为标量子查询( Scalar Subqueries)
select dept_name, |
修改数据库操作
删除操作
delete from r |
插入操作
insert into course |
插入元组基于一个查询的结果
insert into instructor (name, dept_name) |
更新操作
update instructor |
中级的 SQL
这部分主要介绍更复杂的 SQL 包括:SQL 查询,视图定义,事务,完整性约束,数据定义和授权。
join 表达式
上面介绍的 natural join 是根据相同的属性名称自动 inner join。SQL 支持明确指定 join 的断言,即指定 join 的属性。除了 inner join 还有 outer join。如果没有指定是 inner 还是 outer,一般 join 是指 inner join。
join 条件
使用 on 关键字可以指定 join 要关联的属性。
select * |
outer join
inner join 取的是两个关系表属性的交集,outer join 可以取某一个关系表的全部元组,或者两个关系表的全部元组,没有关联的元组其它属性用 null 表示。
outer join 分为:
- left outer join:保留 join 语句前面的那个关系表的所有元组。
- right outer join:保留 join 语句后面的关系表的所有元组。
- full outer join:保留两个关系的所有元组。
outer join SQL 语句:
select * |
join 用在子查询中:
select * |
使用 where 子句代替 on 的断言
select * |
视图
有时我们不希望用户看到全部的逻辑模型。出于安全考虑我们需要对用户隐藏一些数据。我们可以创建一个个性化的关系集合给用户查询,而不用整个逻辑模型。SQL 允许一个通过一个查询定义一个虚拟关系表。这个关系包含查询的结果。虚拟关系不是预先计算和存储的,而是每当使用虚拟关系时通过执行查询计算的。视图(View)不是逻辑模型的一部分,而是一个虚拟关系使用户可见的。
视图的定义
使用 create view 命令定义视图。表达式语法格式如下:
create view v as <query expression> |
视图定义的例子:
create view faculty as |
使用视图
一旦我们定义了一个视图,我们可以使用视图名称作为一个虚拟关系。查询视图和查询正常的关系表是一样的。
select dept_name |
物化视图
一些数据库系统允许视图关系被存储,当实际的关系改变时,视图是更新的,这样的视图称为物化的视图(Materialized View)。保持物化的视图更新的过程称为物化视图维护(Materialized View Maintenance),简称视图维护。
视图维护可以是及时的,关系改变时视图立刻更新;也可以是懒惰的,当视图访问的时候更新视图;另外也可以周期的更新视图。
如果用户频繁的使用视图,物化视图是有益的。视图可以快速的响应查询,避免读取大量的关系。物化视图可以带来好处,但也需要考虑它的不利因素,如存储空间的花费和视图更新操作需要的性能消耗。
更新视图
直接修改视图关系一般是不允许的。有些数据库允许更新视图。
事务
事务是由一系列 SQL 语句组成的一个逻辑单元。事务具有原子性。一个事务通过一个语句表示开始,通过一个语句表示结束。结束一个事务有两种操作,一个是提交,一个是回滚,其中某个操作必须发生且仅有一个操作发生。事务执行中没有任何错误发生,最终会执行提交。事务执行中出现错误,会执行回滚操作,数据库会回滚到事务开始时最初的状态。
当事务由多个 SQL 语句组成,单个 SQL 语句的自动提交需要关闭,使用应用程序接口,如 JDBC 或 ODBC 可以定义事务和关闭事务自动提交。
完整性约束
完整性约束(Integrity Constraint)确保数据库的改变不会丢失数据的一致性。常见的完整性约束,如名称不能为空。不能存在相同的 ID。预算金额必须大于0等等。
完整性约束通常是数据库模式(Schema)设计过程的一部分。完整性约束的声明是 create table 创建关系的一部分。完整性约束可以使用 alter table <table-name> add constraint 语句添加到已存在的关系中,当 alter 命令执行时,系统第一次会验证当前关系是否满足这个约束,不满足则拒绝这个添加约束命令。
单表的完整性约束
单表的完整性约束有:
- not null
- unique
- check
name varchar(20) not null |
参考完整性约束
参考完整性(Referential Integrity)它确保出现在一个关系中指定的属性值,也出现在另一个关系中。
foreign key 子句可以定义在 create table 语句中,定义个参考完整性约束。如:
foreign key (dept_name) references department |
在 SQL 中,外键一般时参考另一个关系的主键。然而,只要参考候选键(Candidate Key)就行,如主键属性,或者唯一约束属性。
当一个参考完整性约束违反时,这个语句时被拒绝执行的。然而,foreign key 子句可以定义在参考的关系违反约束时指定一个删除或者更新操作,系统可以改变参考关系恢复约束,而不是拒绝执行。on delete cascade 子句在外键中声明,可以删除对应的参考关系元组,来满足约束。
foreign key (dept_name) references department |
SQL 也允许 foreign key 子句指定其它非 cascade 的动作。如使用 set null, set default 代替 cascade。
如果存在跨多个关系的一串外键依赖关系,则该链一端的删除或更新会在整个链中传播。
外键属性允许 Null 值,null 值自动满足参考完整性约束。
复杂的检查条件和断言
SQL 支持子查询在 check 子句中,如
check (time slot id in (select time slot id from time slot)) |
复杂的检查条件是有用的,但是也是有性能消耗的。每次插入或更新都要进行检查。
断言(Assertion) 是一个断言条件,数据库总是满足的。域约束和参考完整性约束是一个特殊形式的断言。断言的 SQL 形式如下:
create assertion <assertion-name> check <predicate>; |
复杂的断言是耗费巨大的,使用时要谨慎。
当前,没有一种广泛使用的数据库系统支持 check 子句中的子查询或断言。然而,相同的功能可以通过触发器实现。
SQL 数据类型和 Schema
除了整数,浮点数和字符类型,SQL 还支持其它的内置数据类型。
SQL 中的日期和时间类型
- date:包含年月日等信息。
- time:包含时分秒。
- timestamp:date 和 time 的结合。
日期和时间的值具体格式如下:
date ’2001-04-25’ |
SQL 支持提取时间或日期中的单独的字段。如,提取日期中的年或月。
SQL 定义了一些函数取获取当前日期和时间。如,current_date(),current_time()。具体参考相关的数据库系统的实现。
SQL 允许时间日期数据使用算术和比较操作。如 select x - y , wher x < y
默认值
SQL 允许指定一个属性的默认值,通过 default 关键字进行指定。当插入语句没有给一个属性赋值时,则使用指定的默认值。
age int default 18 |
创建索引
索引(Index)是一个数据结构允许高效地查找属性值,而不用扫描一个关系中的所有元组。一个广泛使用的索引类型为 B+树索引。SQL 语言没有正式的定义索引的语法,大多数数据库系统支持索引创建语言如下:
create index studentID_index on student(ID); |
大对象类型
很多当前的数据库应用需要存储特别大的属性,如一张图片,视频剪辑等等。SQL 提供大对象数据类型: clob (character data)和 blob (binary data),其中字母 lob 表示 Large Object。
book review clob(10KB) |
取出一个完整的大对象到内存中是不高效的或不实际的。SQL query 将取出大对象的 locator(定位器),通过 locator 处理对象。
用户自定义的类型
SQL 支持创建用户自定义类型。有两种格式的类型:distinct types 和 structured data types。使用 create type 子句定义一个类型:
create type Dollars as numeric(12,2) final; |
创建表扩展
SQL 支持创建一个与某个表有相同的 schema 的表,使用 create table ... like 语句。
create table temp_instructor like instructor; |
创建一个表包含一个查询的结果,使用 create table ... as 语句。如:
create table t1 as |
with data 表示包含数据,然而很多数据库实现默认包含数据,with data 子句可以忽略。
Schema, Catalogs, and Environments
数据库系统提供了一个三层等级的命名关系。顶层是 catalog,它包含下一层的 schema,每个 schema 包含多个 SQL 对象如关系表,视图等。
每个用户有一个默认的 catalog 和 schema。默认的 catalog 和 schema 为每个连接设置 SQL 环境的一部分,该环境还包括用户标识符(也称授权标识符)。所有常见的 SQL 语句都是在一个 schema 上下文中运行的。
授权
SQL 标准包含的权限(Privilege)有:select,insert,update和delete。所有权限使用 all privileges 表示。当一个用户执行一个 查询或更新时,系统授权检查该用户是否有这个权限。如果没有则拒绝执行。最终的权限是通过数据库管理员给定的。
权限的授与和撤销
grant 语句可以用来授予权限,权限可以授予给用户和角色。grant 语句格式如下:
grant <privilege list> |
授权的例子:
grant select on department to Amit, Satoshi; |
revoke 语句可以用来撤销权限,revoke 语句的语法格式和 grant 类似,撤销权限的例子:
revoke select on department from Amit, Satoshi; |
角色
在现实生活中,一些用户有相同的权限。管理源需要重复的为某些用户授予权限。为了解决这个问题可以使用角色来给用户授权。先把权限授予给角色,然后把角色授予给用户。这样可以方便的管理用户权限。
创建一个角色语句的例子:
create role instructor; |
给角色授予权限的例子:
grant select on takes |
把角色授权给用户的例子:
grant instructor to dean; |
权限的传递
一个用户的权限授予给另一个用户。使用 with grant option 子句,如
grant select on department to Amit with grant option; |
高级的 SQL
编程语言执行 SQL
SQL 是一个强大的声明式查询语言。SQL 不是图灵完备的,所以数据库应用不能使用 SQL 开发。应用程序一般用 C, C++ 或 Java 实现,通过嵌入 SQL 来访问数据库。
应用程序访问数据库的两种方式:
- 动态的 SQL(Dynamic SQL)。程序在运行时构造一个 SQL 语句。通过应用程序接口提交 SQL 语句给数据库服务器,得到返回结果。常见的应用程序接口,如 JDBC 是 Java 语言连接数据库的应用程序接口。ODBC 是 C 语言的应用程序接口。
- 嵌入的 SQL(Embedded SQL)。在程序编译之前,使用预处理器将 SQL 语句给数据库系统预编译和优化,将程序中的 SQL 语句代替合适的代码。
JDBC
JDBC (Java Database Connectivity)标准定义了一个应用程序接口(API),让 Java 程序能够连接数据库服务器。不同的数据库系统有不同的 JDBC 实现。
JDBC 主要的操作:
- 与数据库建立连接。
- 传送 SQL 语句给数据库系统。
- 取出 SQL 执行的结果。
- 调用方法和存储过程。
- 获取数据库元数据。
- 执行事务。自动提交。
方法和存储过程
存储过程(Procedure)和方法(Function)允许一系列 SQL 操作存储在数据库,通过 SQL 语句调用执行。
它的优点:
允许多个应用程序访问。
一处修改多处使用,存储过程的逻辑改变,不需要修改其它应用程序。
应用程序调用存储过程,而不是直接的修改数据库关系。
SQL 标准定义了存储过程的语法标准,但是大部分数据库的实现是不标准的版本。
声明和调用方法和存储过程
SQL 标准的方法和存储过程例子:
create function instructors_of (dept_name varchar(20)) |
create procedure dept_count_proc(in dept name varchar(20), out d_count integer) |
调用存储过程的 SQL 语句。
declare d_count integer; |
存储过程和方法的不同:
- 存储过程是预编译的对象,而方法每次调用都要编译。
- 存储过程有输入参数和输出参数,而方法只有输入参数。
- 存储过程不包含 return 语句,可以返回 0 个或多个值。而方法有 return 语句,必须且仅有一个返回值,返回值可以是基本类或者组合类型。
- 方法可以调用存储过程,反之不能。
触发器
触发器(Trigger)是一个语句在触发事件时自动执行的。
触发器的用途:
- 实现一些完整性约束,当 SQL 的约束机制不能实现的。
- 启动一些自动任务。
定义触发器的 SQL 例子:
create trigger timeslot_check1 after insert on section |
大部分数据库触发器实现的语法是不标准的。具体的情况,需要参考具体数据库的用法。
触发器可以设置启用或关闭。
触发器应该小心使用,因为运行时检测到触发器错误会导致出发该触发器的操作语句执行失败。触发器是有用的,但是当存在替代方案时最好避免使用触发器。
形式关系查询语言
关系型查询语言(如 SQL 语言)是基于形式模型的。常见的形式关系查询语言(Formal Relational Query Language)如下:
- 关系代数(Relational Algebra)
- 元组关系演算(Tuple Relational Calculus)
- 域关系演算(Domain Relational Calculus)
关系代数
关系代数(Relational Algebra)是一个过程的查询语言。它由一组操作组成,把一个和多个关系作为输入,产生一个新的关系作为结果。
基本的操作有:select,project,union,set difference,Cartesian product,rename。
其它操作:set intersection,natural join,assignment。
关系代数表达式的例子:
select
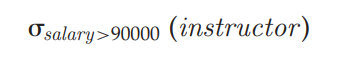
project
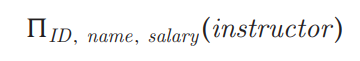
set union
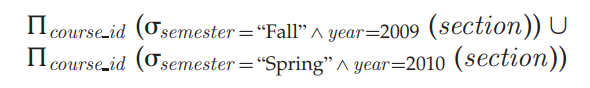
set intersection
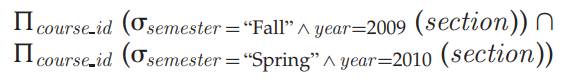
set difference
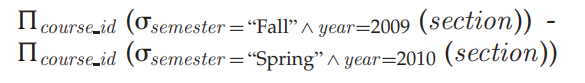
Cartesian product
rename
natural join
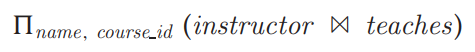
assignment
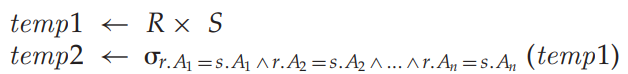
left/right/full outer join
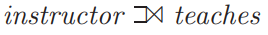
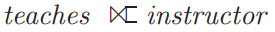
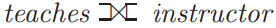
arithmetic operations
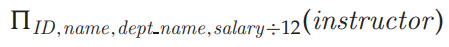
aggregate functions
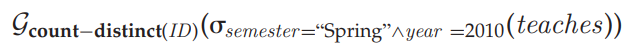
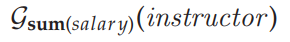
元组关系演算
元组关系演算(Tuple Relational Calculus)是一个非过程查询语言。一个元组关系演算的查询表示形式如下:
{t | P(t)} |
t:表示所有的元组
P:表示断言。
t[A]:表示元组t中的属性A。
t ∈ A:表示元组 t 在关系 r 中。
元组关系演算查询表达式的使用例子:
{t | t ∈ instructor ∧ t[salary] > 80000} |
{t | ∃ s ∈ instructor (t[ID] = s[ID] ∧ s[salary] > 80000)} |
{t | ∃ r ∈ student (r[ID] = t[ID]) ∧ |
域关系演算
域关系演算(Domain Relational Calculus)是另一种关系演算的查询语言。它的表达形式如下:
{< x1, x2,..., xn > | P(x1, x2,..., xn)} |
x1, x2,…, xn 表示域变量,P 表示操作公式。
使用例子:
{< i, n, d,s > | < i, n, d,s > ∈ instructor ∧ s > 80000} |
{< n > | ∃ i, d,s (< i, n, d,s > ∈ instructor ∧ s > 80000)} |
无论是关系型代数,元组关系演算,还是域关系演算,每一个表达式都是由若干个基本操作组成的,所以,这三种形式关系查询表达式,可以互相转换。
在数据库系统中,一个查询的 SQL 语句,必须先转换为关系代数查询表达式,然后执行相关查询操作,因为关系代数查询表达式是过程的,它明确了执行哪些基本的操作,而 SQL 没有指定执行哪些基本操作。
小结
SQL 的细节实在是太多了,我们来小结一下。
SQL 内置的数据类型
| 基本的类型 | 时间类型 | 大对象类型 |
|---|---|---|
| char(n) varchar(n) int smallint numeric(p, d) real, double precision float(n) |
date time timestamp |
clob blob |
SQL DDL
- 定义表:定义表的属性和数据类型,定义完整性约束,定义参考完整性约束。
- 定义索引。
- 修改表:添加/删除表字段、添加/删除表的约束。
- 删除表。
- 授权。
- 定义/删除:视图、存储过程、方法和触发器。
常见的完整性约束
- not null
- unique
- check
- referential Integrity
SQL DML
- 插入,修改,删除和查询元组。
SQL DML 的查询操作
- 基本的单表查询。select … from … where,去重(distinct, all),算术表达式,逻辑连词(and, or, not)。
- 基本的多表查询。from Cartesian product,natural join,outer join
- 其它基本的 SQL 查询操作。as(rename),like(string),order by,limit
- 集合操作。union,intersection,except
- 聚合函数和 having 子句。
- 嵌套子查询。
SQL DML 的查询总结
| 子句 | 关键字 | 聚合函数 | 字符串函数 |
|---|---|---|---|
| select from where group by having order by |
as distinct, all natural join, inner join, left join, right join, full join union, intersect, except between, in like and, or, not limit |
avg() min() max() sum() count() |
length() concat(str1, str2, …) concat_ws(separator, str1, str2, …) trim() locate() substring() upper() lower() repeat() reverse() replace() ascii() bin() hex() |
深入理解数据库系统系列文章
References
[1] Database System Concept (6th) by Avi Silberschatz, Henry F. Korth, and S. Sudarshan